网站首页 文章专栏 一刻相册批量导出
背景
2021 年 1 月毕业的时候,我卖掉了自己的星际蜗牛,自己在上面搭建的 nextcloud 也就不能用了。为了让自己的相册等个人文件有个好去处,我开始尝试使用一刻相册,当时吸引我的有如下几个优点:
- 不限容量,我有大概几千张图片和几百个视频,容量在 20-30 G 之间;
- 多端应用,pc 和手机端都有,且手机端可以自动备份;
- 访问速度快,这点也很重要,自己的 nextcloud 因为要走内网穿透,比较慢。
使用了近 10 个月后,我决定放弃使用一刻相册,原因如下:
- 没有批量导出功能,令人担忧;
- 照片多了之后需要有分类功能,但是好用的功能都要收费。
目标
目前在一刻相册上有 6000 余张照片,40 余条视频,共计存储空间 20 G。将这些内容导出到电脑本地存储,待后续寻找更优的解决方案。
技术方案
首先停止新照片的上传,早在两三个月前已经实施,当前有 300 张照片未同步,这些照片存储在手机中。
然后,使用某种方法将一刻相册中的数据导出,提出以下几种技术路线:
提出下面的技术路线:
- 使用 pyautogui 模拟鼠标与键盘;
- 使用 selenium 控制浏览器;
- 分析 api 使用 requests 请求。
其中 1 根据控件定位方式的不同分化为两个方案,2 的环境配置较为复杂,对 driver 和 chrome 的配对要求较高,没有考虑。
下载图片的主要操作流程是在预览页面,先点击下载按钮,再点击存储,最后点击下一张,之后重复上述三步。
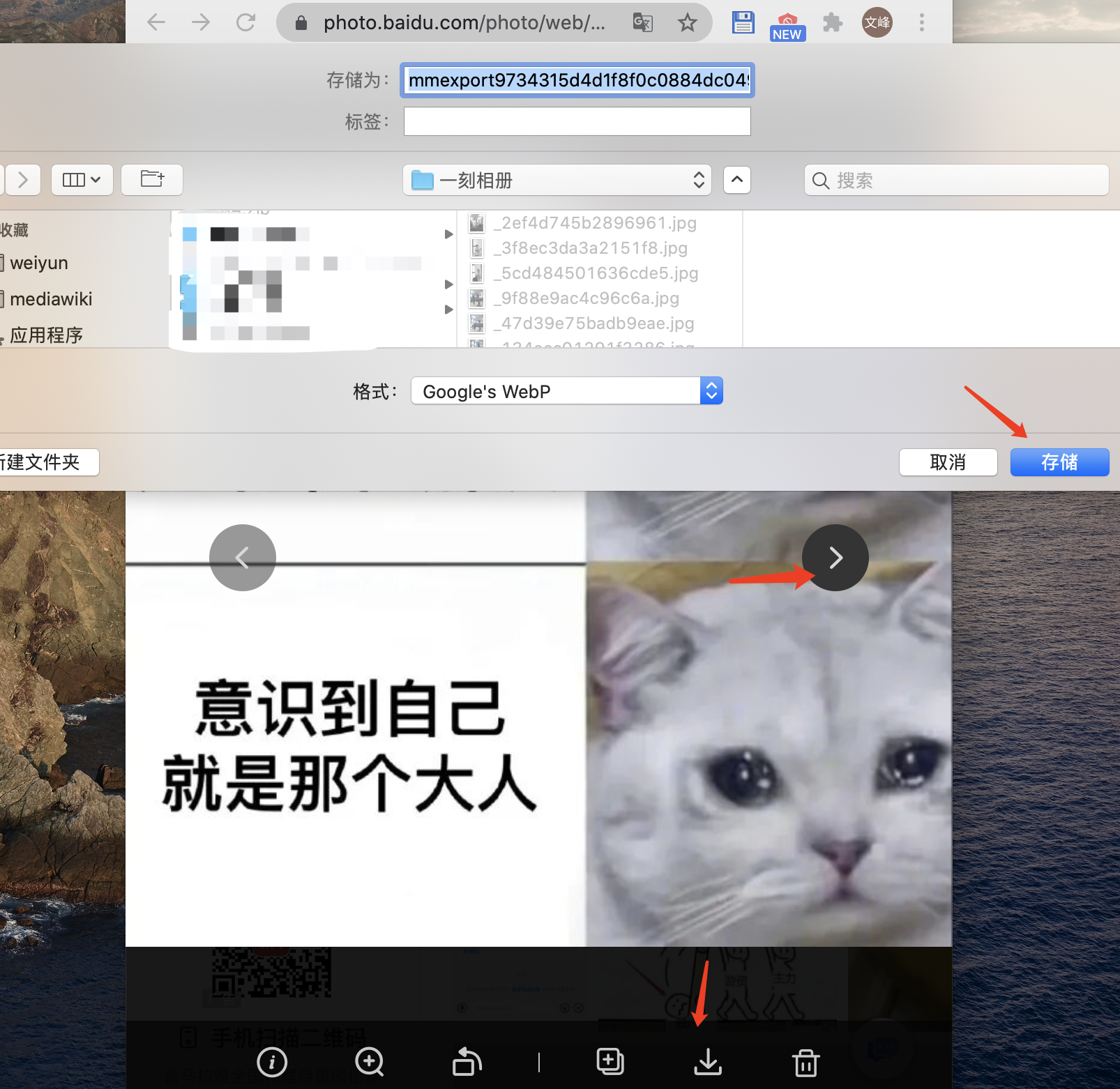
各方案实现细节
方案一:pyautogui 使用图片对控件进行定位
浏览器登录一刻相册,使用 python 的 pyautogui 的图片定位功能。控件共三个,即下载按钮、存储按钮、下一个按钮。分别截图并保存,然后在 pyautogui 中使用 locateOnScreen 函数定位,关键代码如下
def locate_run():
# 定位下载按钮
download_pos = pg.locateOnScreen(image="./yike_download.png")
if download_pos is None:
print("locate download failed")
return
# 按下下载按钮并等待几秒
print("locate success")
target = pg.center(download_pos)
pg.moveTo(target)
print("move to ", target)
pg.click()
time.sleep(2)
save_pos = pg.locateOnScreen(image="./yike_save.png")
if save_pos is None:
print("locate save failed")
return
print("locate save success")
target = pg.center(save_pos)
pg.moveTo(target)
print("move to ", target)
pg.click()
time.sleep(2)
next_pos = pg.locateOnScreen(image="./yi_next.png")
if next_pos is None:
print("locate next failed")
return
print("locate next success")
target = pg.center(next_pos)
pg.moveTo(target)
print("move to ", target)
pg.click()
time.sleep(0.5)
很快发现问题,图片定位经常失败,猜测是因为屏幕分辨率太高,而截图分辨率低。该方案不可用。
方案二:pyautogui 使用绝对位置移动鼠标
相比于上个方案,这次是提前固定好浏览器的位置,然后记录三个位置的绝对坐标,最后开始运行程序。
先使用代码捕获当前鼠标的坐标,以便完成定位:
def inspect():
try:
while True:
x, y = pg.position()
print(x, y)
time.sleep(0.5)
except KeyboardInterrupt:
print('\nExit.')
再完成三个控件的点击逻辑:
def direct_run():
pos_list = []
# 三个坐标分别是<下载、存储、下一个>三个控件的坐标
pos_list.append((1550, 1020))
pos_list.append((1747, 528))
pos_list.append((1681, 580))
for i in range(len(pos_list)):
pos = pos_list[i]
pg.moveTo(pos, duration=0.3)
print("move to ", pos)
time.sleep(3)
pg.click()
试用后发现一刻相册对图片和视频的展示做了区分,控件的位置不同。好在自己的视频不多,通过手工的方式下载视频,并逐一删除,保证一刻相册内全部是图片,继续导出。
之后发现在刚开始运行程序时,操作系统 GUI 界面的焦点在 pycharm 上,虽然移动鼠标到了浏览器的下载按钮,但仍需要先点击一次让浏览器获取焦点,再点击一次弹出下载框。所以程序刚开始运行时需要点击两次,运行后只需要点击一次。提取出一个让浏览器获取输入焦点的函数:
def focus():
# 这个坐标是浏览器的任意空白位置
pg.moveTo((1550, 1000))
pg.click()
随后发现有些图片比较大,有些图片比较小,预留的时间不够,点击下载按钮后不能在时限内弹出下载框,而程序继续往后运行(点击<下一个> 控件),可能会错过一些图片。再次观察发现如果浏览器的位置合适,在弹出下载框的时候浏览器界面整个左移,导致原有控件坐标失效,接下来的点击操作也无法生效,相当于整个操作停止了,不会跳过图片,只是浪费操作一轮的时间而已。
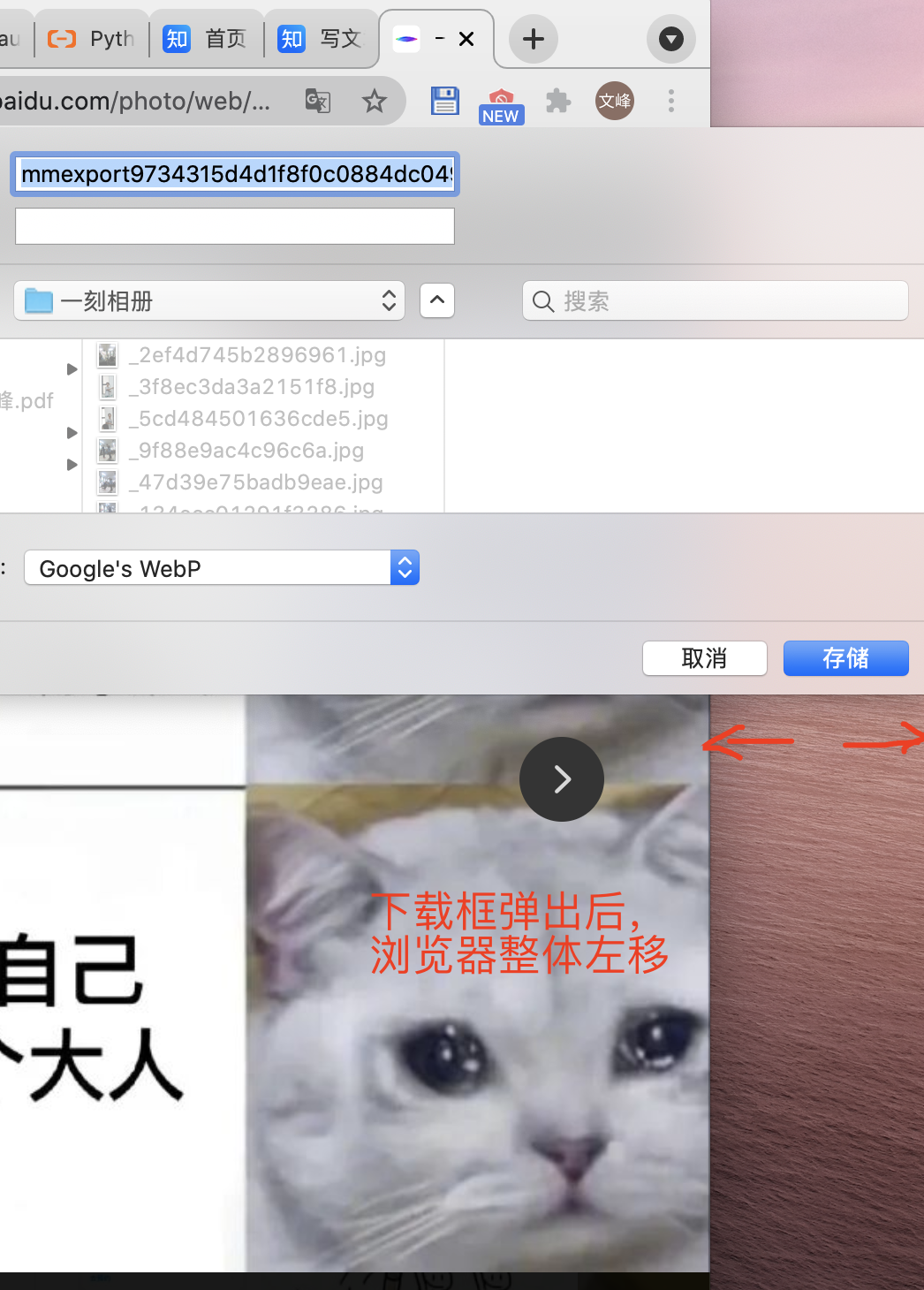
再次运行一段时间后发现预览页的<下一个>控件点击不了,是因为当前页面只加载了一部分照片,那么也就只能预览这一部分照片。解决方案是回到主页,不断下拉直到所有图片加载完成,再重新开始导出。代价是网页加载了 6000 多张照片后开始卡顿,导出速度进一步变慢。在一段时间后预览页面无法加载预览图,但仍可下载。
继续运行一段时间后发现这个流程很耗时。我有约 6000 张图片,算了下全部导出需要十几个小时,这是不可接受的。开始考虑其他方案。
方案三:分析 api,使用 requests 模拟浏览器请求
分析 api 是比较耗时的,并且是重点防范的违规利用方式,必然有严苛的措施,所以这是我最后才考虑的方案。幸运的是一刻相册并没有做很多的反爬措施。
分析后发现有两个 api 非常重要,分别是列表页和直链获取。
鉴权
为简便起见,不再从用户登录开始分析,直接从登录后的 cookies 入手,避免登录页可能的反爬措施。
在 chrome 浏览器访问一刻相册,保存列表页的请求为 HAR 文件。
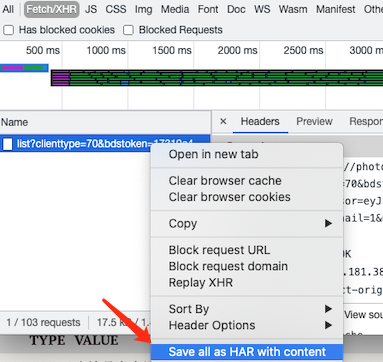
用文本方式打开 HAR 文件,搜索键值为 cookies 的数组,将数组另存为 yike_cookies.json文件。
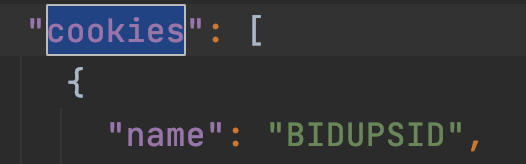
之后完成从文件中读取 cookies 的逻辑:
def request_load_jar():
jar = req.cookies.RequestsCookieJar()
with open("yike_cookies.json", encoding="utf8") as f:
cookies = f.read()
cookies = json.loads(cookies)
for cookie in cookies:
# jar.set(cookie["name"], cookie["value"], domain=cookie["domain"], path=cookie["path"])
jar.set(cookie["name"], cookie["value"])
# print(jar)
return jar
列表页
顾名思义,向浏览器请求一个图片列表回来。
GET https://photo.baidu.com/youai/file/v1/list
请求参数,url 编码
| key | TYPE | value |
|---|---|---|
| clienttype | int | 应该是客户端类型,浏览器规定为 70 |
| bdstoken | string | 与用户相关的某个 token,在浏览器的开发者模式可看到,整个交互过程中固定为一个值,直接复制粘贴 |
| need_thumbnail | int | 是否需要缩略图, 1: 需要; 0: 不需要 |
| need_filter_hidden | int | 含义不明,暂定为 0 |
| cursor | string | 当前图片的光标,如果没有该值,会从第一张图片开始返回 |
返回参数,json
| key | TYPE | value |
|---|---|---|
| errno | int | 错误码,-6: 猜测是未授权;0: 正常 |
| has_more | int | 是否还有图片, 1: 有; 0: 没有 |
| cursor | string | 新坐标 |
| list | array | 图片列表 |
图片列表中的元素较多,不一一列出,只给出关键的字段
| key | TYPE | value |
|---|---|---|
| fsid | int | 图片在一刻相册的 id |
| path | string | 上传的时候图片的路径,可以提取 basename 做文件名 |
根据接口要求,写获取所有图片信息的函数:
bdstoken = "your token"
def request_get_list():
jar = request_load_jar()
cursor = ""
has_more = 1
all_list = []
# 循环获取所有列表
while has_more:
print("cursor is ", cursor)
list_url = "https://photo.baidu.com/youai/file/v1/list"
params = {
"clienttype": 70,
"bdstoken": bdstoken,
"need_thumbnail": 1,
"need_filter_hidden": 0
}
if len(cursor) != 0:
params["cursor"] = cursor
r = req.get(url=list_url, cookies=jar, params=params, headers=headers)
ret_json = r.json()
errno = ret_json["errno"]
if errno != 0:
print("errno not 0")
print(ret_json)
print(r.status_code)
print(r.request.url)
print(r.request.headers)
break
has_more = ret_json["has_more"]
cursor = ret_json["cursor"]
num = len(ret_json["list"])
print("获取了 %d 张图片信息" % num)
all_list.extend(ret_json["list"])
print("当前共计 %d 张图片信息" % len(all_list))
print("第一张图片是 %s" % ret_json["list"][0]["path"])
time.sleep(1)
# print(ret_json)
with open("all_list.json", "w", encoding="utf8") as f:
f.write(json.dumps(all_list))
直链获取
操作逻辑是先拿 fsid 请求下载接口,得到直链,然后再请求直链,得到真实图片数据。
GET https://photo.baidu.com/youai/file/v2/download
请求参数,url
| KEY | TYPE | VALUE |
|---|---|---|
| clienttype | int | 客户端类型,暂定为 70 |
| bdstoken | string | 某个固定的 token 值,在浏览器中获取 |
| fsid | string | 文件的唯一 id,从列表页接口获取 |
返回参数,json
| KEY | TYPE | VALUE |
|---|---|---|
| errno | int | 错误码,-6: 猜测是未授权;0: 正常 |
| dlink | string | 直链 |
之后再请求直链即可完成下载。
根据以上 api,完成直链获取与图片数据下载逻辑:
bdstoken = "your_token"
save_path = "/Users/wenfeng/Downloads/一刻相册"
download_url = "https://photo.baidu.com/youai/file/v2/download"
num_process = 2
q = mp.Queue(maxsize=num_process * 2)
def request_download_thread(queue):
jar = request_load_jar()
while True:
try:
queue_ret = queue.get(timeout=10)
except:
break
print("got from queue")
pic = queue_ret
basename = os.path.basename(pic["path"])
# 先看本地是否已经下载
full_path = os.path.join(save_path, basename)
if os.path.exists(full_path):
print("path %s exists, continue" % full_path)
continue
params = {
"clienttype": 70,
"bdstoken": bdstoken,
"fsid": pic["fsid"]
}
r = req.get(url=download_url, cookies=jar, params=params, headers=headers)
ret_json = r.json()
errno = ret_json["errno"]
if errno != 0:
print("errno 不为 0")
print(ret_json)
print(params)
print(r.request.url)
print(r.request.headers)
print(r.cookies)
break
dlink = ret_json["dlink"]
pic_r = req.get(url=dlink, cookies=jar, params=params, headers=headers)
write_size = 0
with open(full_path, "wb") as f:
write_size = f.write(pic_r.content)
print("save %s ok, size %d k" % (full_path, write_size / 1024))
print("stop")
def request_download():
jar = request_load_jar()
all_list = None
with open("all_list.json", encoding="utf8") as f:
all_list = json.loads(f.read())
print("加载了 %d 条信息" % len(all_list))
# 启动多进程
process = [mp.Process(target=request_download_thread, args=(q,)) for i in range(num_process)]
[p.start() for p in process] # 开启了进程
print("subprocess start ok")
for j in range(len(all_list)):
print("put %d to queue" % j)
q.put(all_list[j])
print("waiting for subprocess to stop")
[p.join() for p in process] # 等待进程依次结束
print("stop")
刚开始没加多进程,下载速度与 pyautogui 不相上下。随后增加多进程,并设置进程数为 3(避免对服务器产生影响),导出速度约 2-3M/s,这个速度可以接受。
随后发现 mac 在执行后台任务且没有前台任务时容易自动休眠,在系统偏好中设置禁止休眠不起作用,下载 Amphetamine 后解决。
最终经过若干小时候,导出 6k+ 图片,共计 20G。
后记
图片下载完成后本来打算全部传到微云集中存储,意外发现由于用微云离线下载了电影,侵犯了版权导致账号被封。搜索后发现解封概率下,其他正常文件也一同消失了。幸好在从百度云脱坑后就改变了自己使用公有云的方式,只做数据同步与备份而不是单一存储,所以失去微云损失可控。
探索自主可控的私有云任重道远。
2021.11.6 后来发现微云只是偶尔抖动导致不可访问,并没有被封禁。考虑目前的各种开源相册实现方案,还是用微云最划算,省事,平时注意多重备份吧。另外删除了微云上的所有版权相关内容,如剧集、电影等,完全存储个人文件。